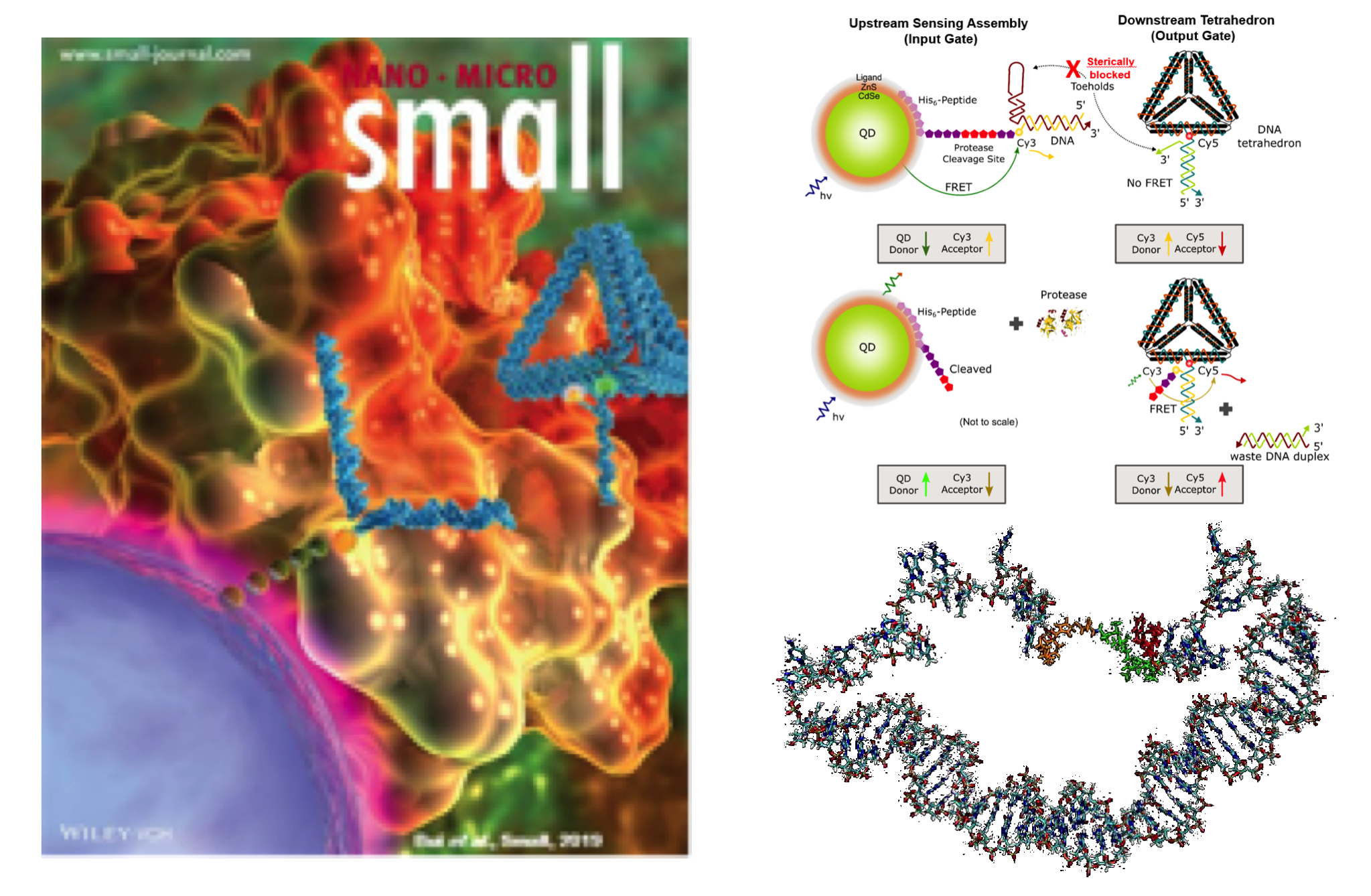
Our group interests are molecular computing, DNA nanotechnology, and synthetic biology. In particular, we seek to understand the molecular interactions and the principle that governs the self-assembly in order to develop computational models to elucidate molecular systems in a predictive and explainable way for general computing purposes. Currently we are seeking to model DNA systems that can perform basic logic for counting and evaluating biomarkers (e.g. miRNA and disease associated proteins) in vitro and in vivo with high accuracy and relatively inexpensive.

BMC group utilizes DNA as the foundational building blocks for many nanotechnology applications.

BMC group engages in multiple research areas including molecular computing, DNA nanotechnology, and synthetic biology.
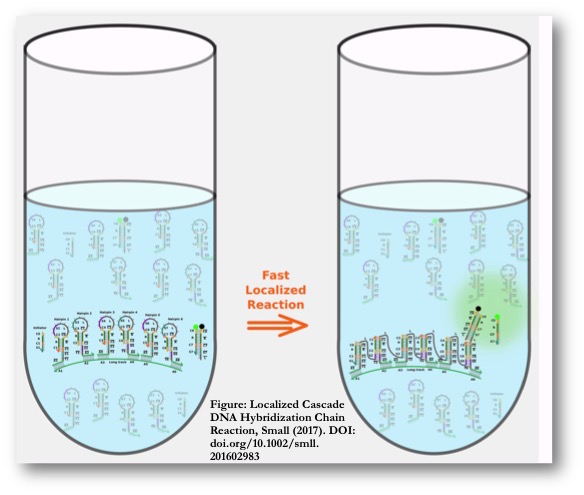
Localized DNA Computation
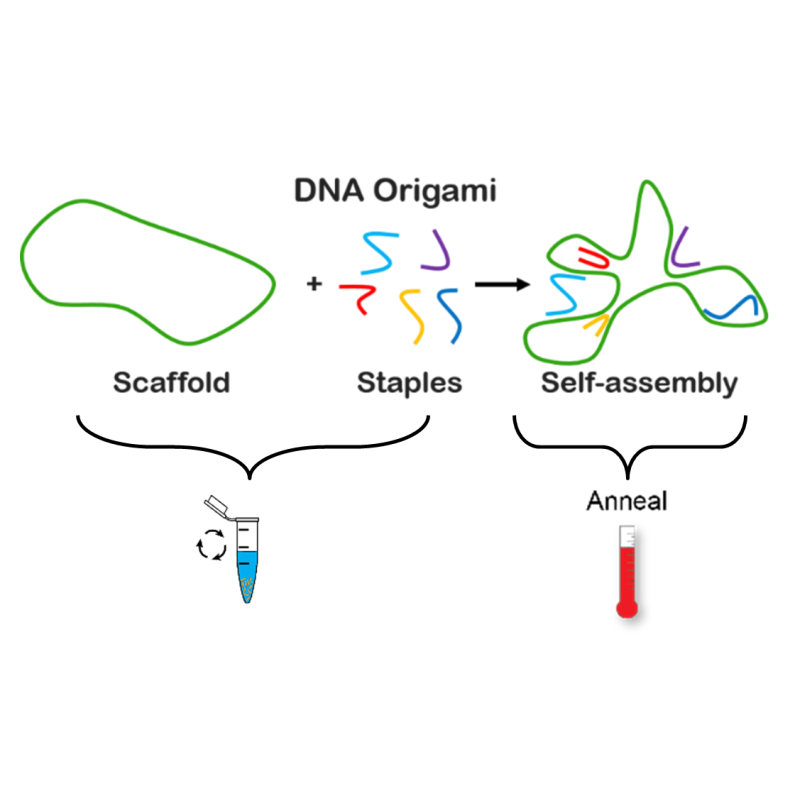
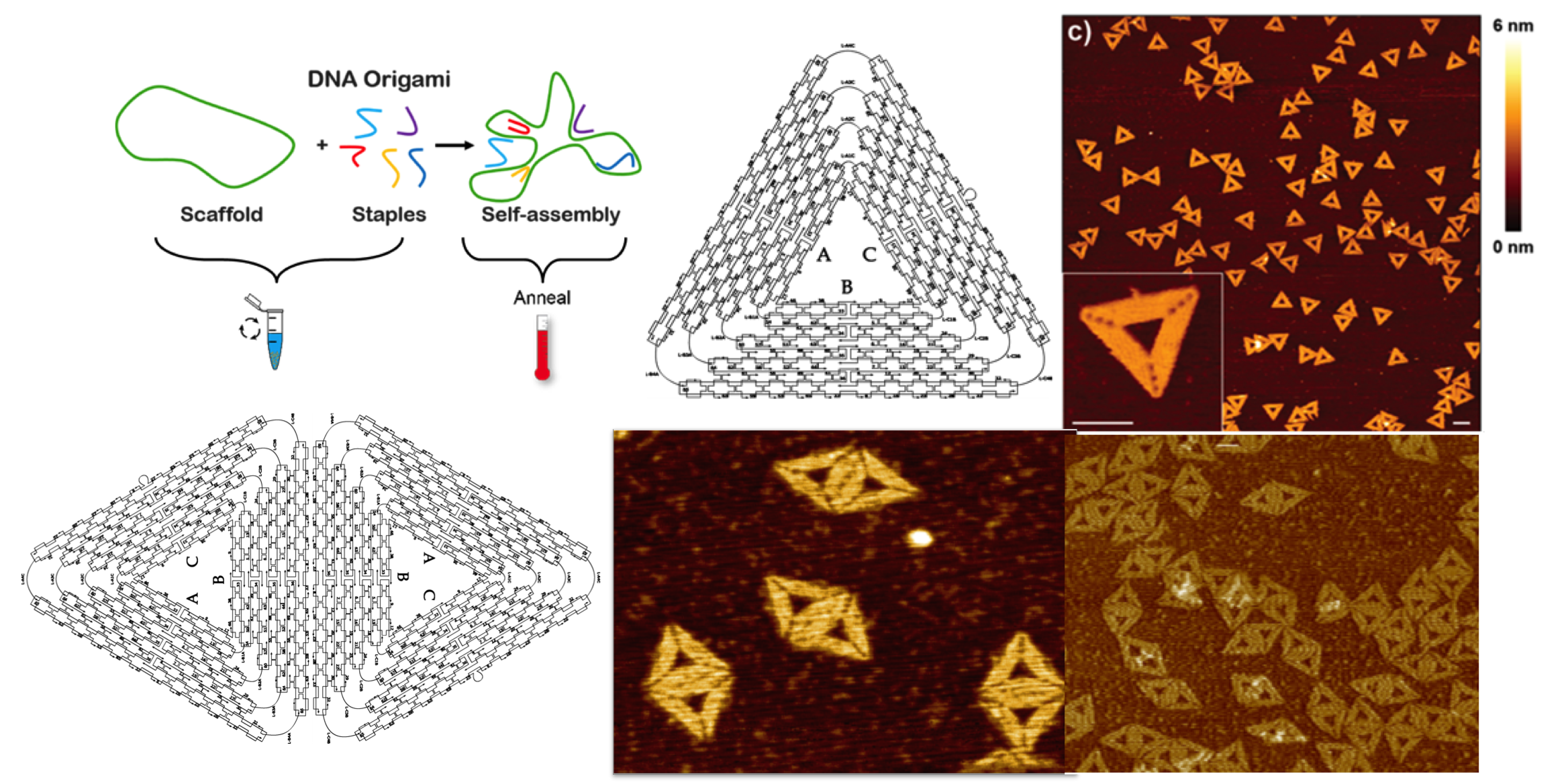
DNA origami is an approach to program nanoscale objects with controllable shapes and sizes.
Research Areas
- Molecular Computing offers many benefits including parallelism and self-assembly. Individual building blocks such as amino acids, RNA or DNA can be programmed and self-assemble into trillions of individual circuits simultaneously in milliliter reaction volumes. Each circuit can then execute its own function independent of other circuits, creating massive parallelism to solve a set of coordinated computations in parallel.
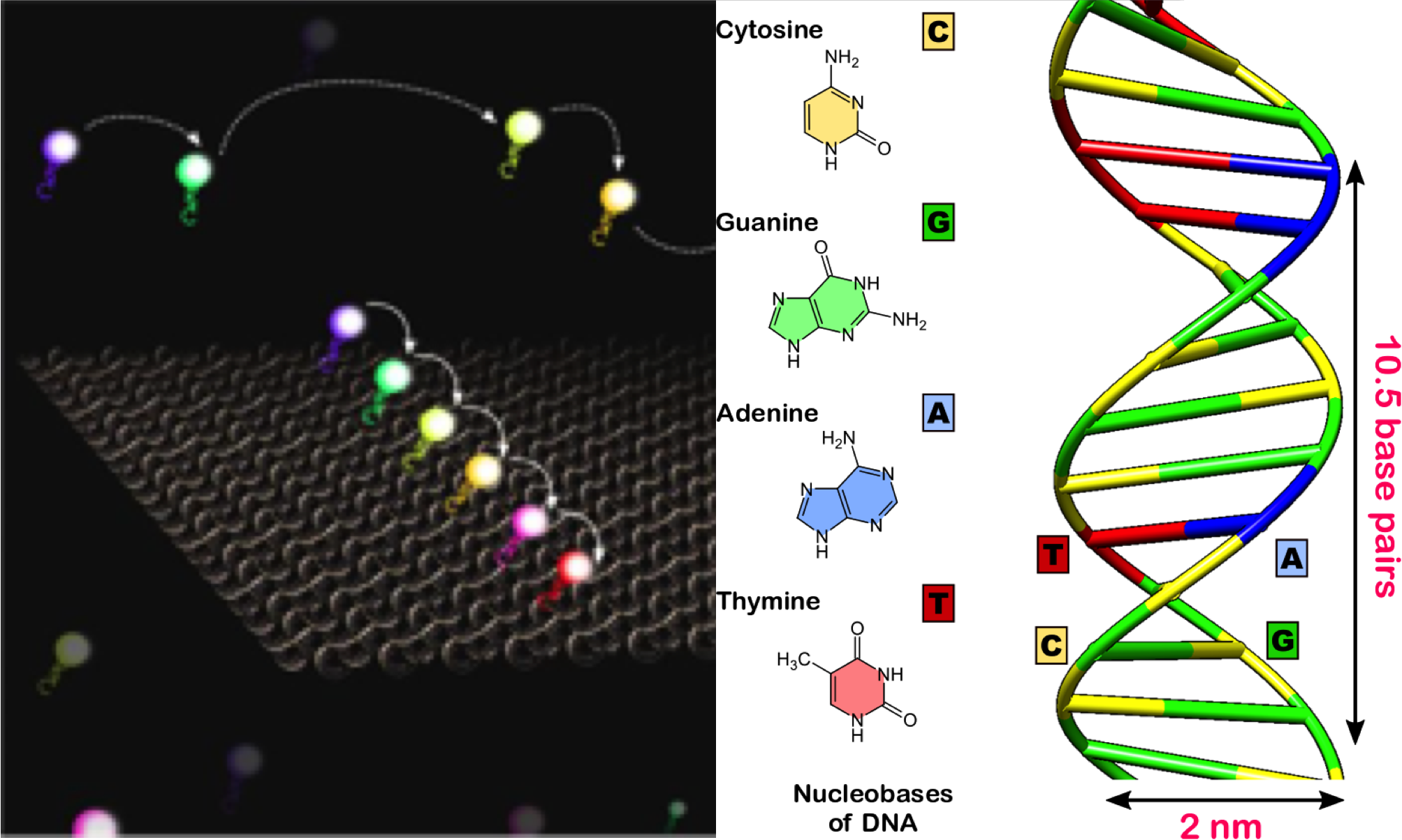
- DNA Nanotechnology provides a means to design, program, and manufacture artificial nucleic acid structures for technological uses. Nucleic acids (RNA/DNA) are utilized as non-biological engineering materials rather than as the carriers of genetic information in living cells. With four excellent properties (self-assembly, programmability, predictability, and molecular recognition), DNA is the molecular choice for building next-generation nano-bio-opto-magneto-electronics from the bottom-up.
- Synthetic Biology provides a means to design, program and fabricate biological components that do not already exist in the natural system via applying engineering principles to biology. In essence, our group aims to re-design of existing biological systems for useful purposes. Ultimately, we seek to build artificial biological systems for research, engineering and medical applications.